📌 프로젝트 목표
- 기업 맥락(현대자동차 디자인 철학·VoC·트렌드)을 반영한 기업 특화 sLLM 개발
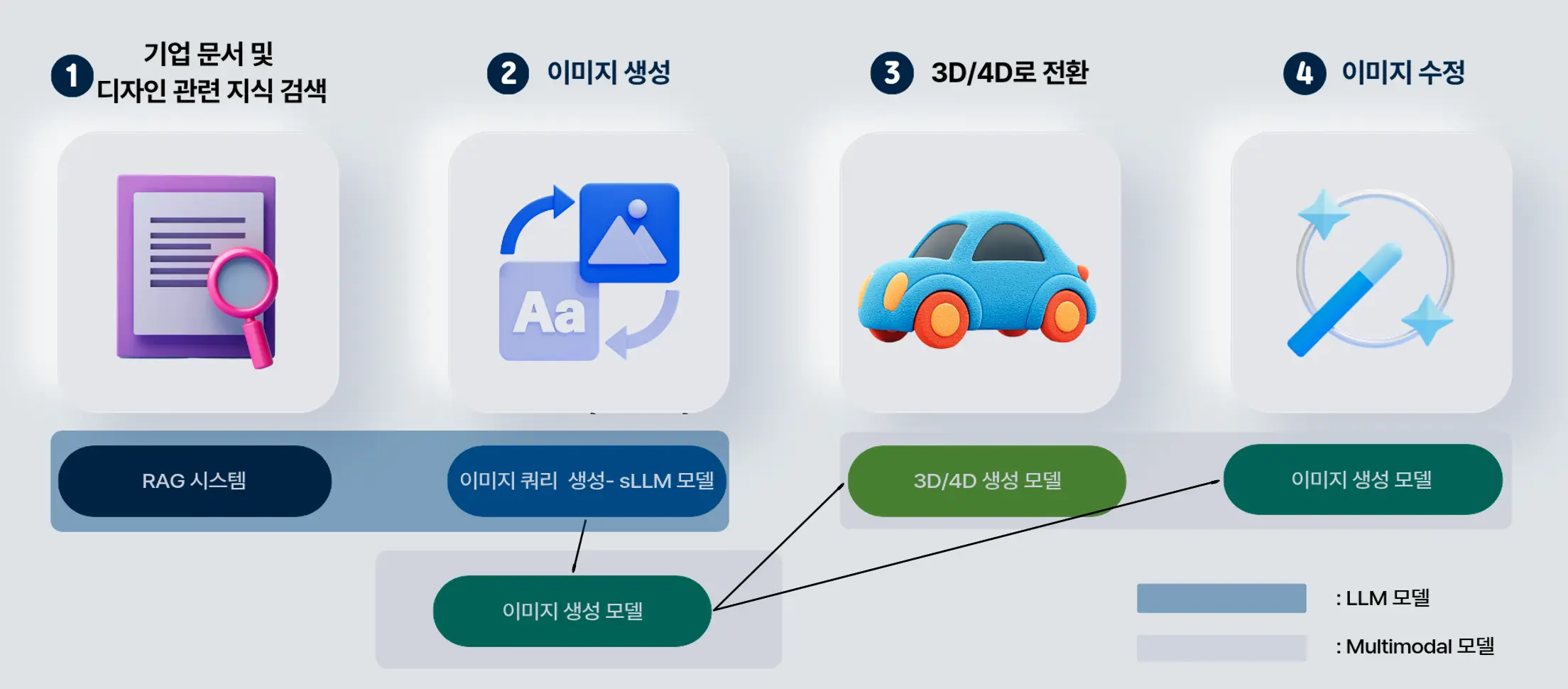
- 자동차 디자이너의 초기 시안 제작·수정·3D/4D 시각화까지 가능한 AI 플랫폼 구축
- 텍스트·이미지·3D·4D 모델을 하나의 통합 파이프라인으로 연결
- Human-in-the-Loop 기반 디자인 체크리스트 → 이미지 생성 → 수정 전체 워크플로우 구성
📌 Why This Project?
- 기존 이미지 생성 모델은 기업의 고유 디자인 언어 반영이 어려움
- 디자이너의 리서치–컨셉–시안 수정 과정을 AI로 보조할 수 있는 가능성 탐색
- LLM + FLUX + 3D + Video 기반 멀티모달 엔드투엔드 파이프라인 구축 경험 확보
📌 My Main Contributions
- Image-to-Text 모델(InternVL3)을 활용한 이미지 특징 추출(Click ▶️)
- sLLM 파인튜닝 데이터셋 구성(Click ▶️)
- AI 파이프라인 총괄(Click ▶️)
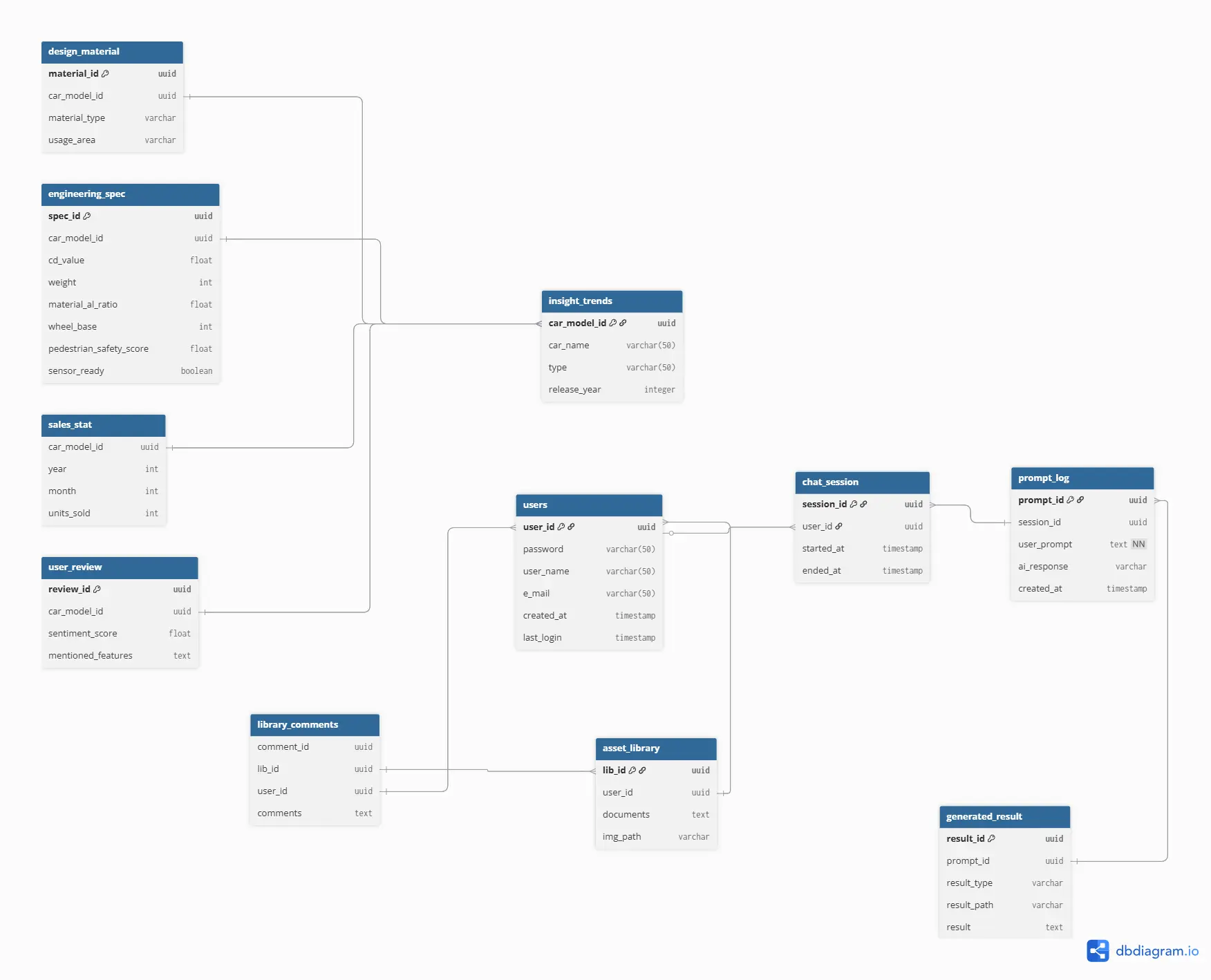
- ERD 설계(Click ▶️)
📌 Other Tasks Included
-
기획 및 설계
프로젝트 목적 설정 → 환경 분석 → 시스템 구성 기획 → 주요 구성 요소 상세 설계 -
데이터 수집 및 전처리
- 이미지 데이터: 현대차 2020~2025 이미지 1,988개 + 컨셉카 56개 (총 17GB)
- 텍스트 데이터: 디자인 논문 4개, 디자인 문서 4개, 기사 12개, 리뷰 1개, 역사 문서 1개 (총 40MB)
- Figma 기반 화면 설계 및 프론트엔드 개발
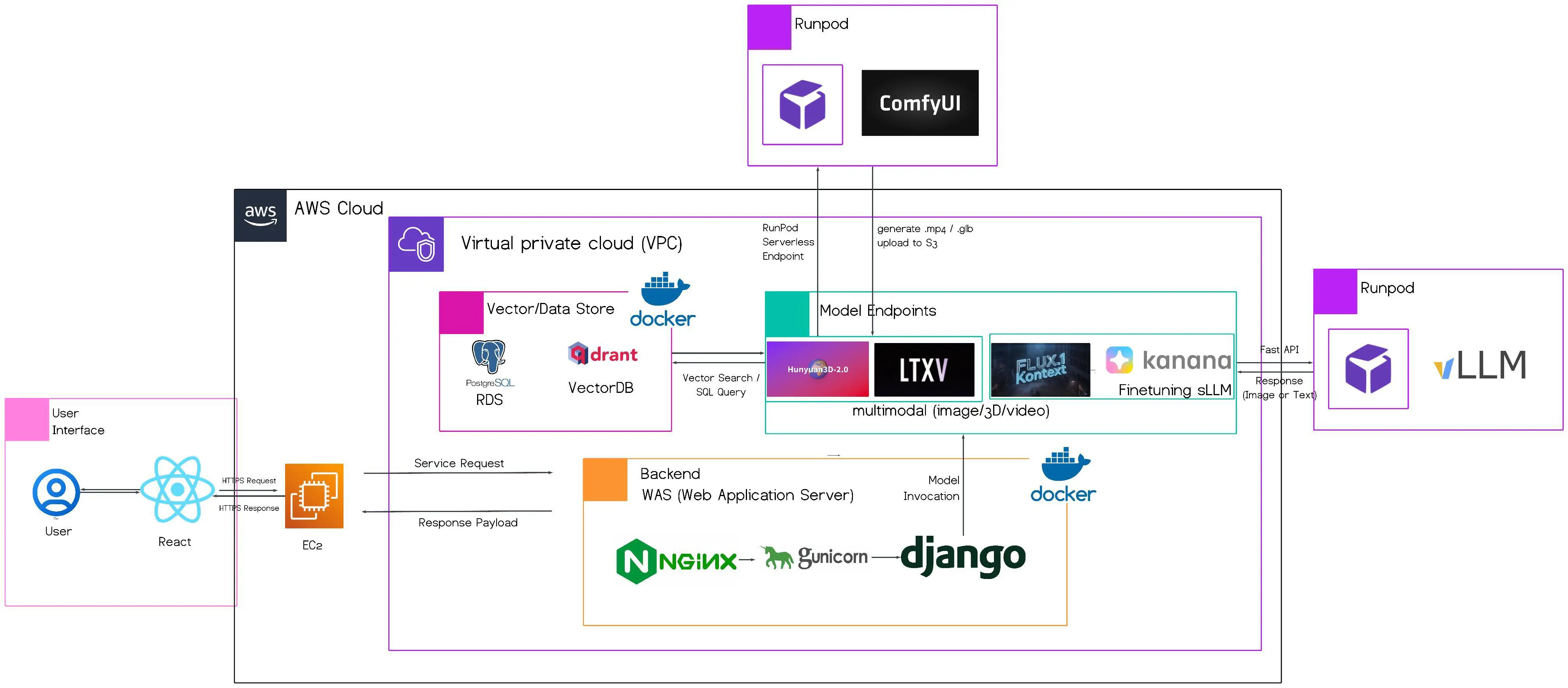
- 백엔드 개발: React UI → EC2 Backend → Model Endpoint → Runpod GPU → S3 Output
📌 Image-to-Text 모델(InternVL3) 기반 이미지 특징 추출
- 오픈소스 모델 중 하나인 OpenGVLab/InternVL3_5-8B-HF 모델을 사용하여 이미지 captioning 작업을 진행
- 아래와 같은 프롬프트 템플릿을 통해 자동차의 주요 특징들을 추출하도록 설정하였으며, 이미지의 경로와 output 결과 jsonl 형태로 저장
prompt = (
"As an automotive designer, briefly and precisely summarize this car's design: body type,
proportions, surface, lighting, grill, wheels, color, unique/futuristic elements."
...lines of code...)
messages = [[
{
"role": "user",
"content": [
{"type": "image", "path": img_path},
{"type": "text", "text": prompt},
],
}
]]

Captioning 결과 예시:
This car features a modern SUV body type with sleek, balanced proportions.
The design includes smooth, flowing surfaces and minimalistic lighting with integrated LED accents.
The grill is narrow and horizontal, contributing to a contemporary look. It has stylish, multi-spoke alloy wheels.
...
📌 sLLM 파인튜닝 데이터셋 구성
-
1️⃣ 원문 문서를 청크 단위로 분할(chunking)
- 해당 레코드의 청크를 긍정(positive) 컨텍스트로 설정
- 다른 청크들에서부정(negative) 컨텍스트 2개 샘플링
- positive/negative를 섞어 순서 랜덤화 및 정답 인덱스(positive_index) 부여
2️⃣ 각 청크를 바탕으로 LLM이 질문–답변(Question-Answer) 3쌍을 생성
3️⃣ 생성된 _chunks_qa.jsonl 입력을 읽어, 각 레코드별로
- Reranker 입력 시,
question(+answer옵션)와contexts를 함께 넣고, 모델로 하여금positive_index를 맞히도록 학습하는 방식
| 필드 | 타입 | 설명 |
|---|---|---|
question | string | (선행 단계) LLM이 생성한 질문 |
answer | string | (선행 단계) LLM이 생성한 답변 |
chunk_text | string | 이 레코드의 원본 청크 텍스트 |
contexts | string | [1] …, [2] …, [3] …형식의 후보 컨텍스트 리스트(positive 1개 + negative 2개) |
positive_index | int | contexts 내 정답(positive) 위치 |
그 외 | any | 원본에서 보존되는 메타데이터(문서 ID, 청크 ID 등) |
{
"... 원본 필드 ...": "...",
"contexts": [
"[1] 컨텍스트_문자열",
"[2] 컨텍스트_문자열",
"[3] 컨텍스트_문자열"
],
"positive_index": [1] // 1-based index, contexts 중 정답(positive) 위치
}
📌 모델 개발 및 파인튜닝
-
[이미지 모델 학습 결과] FLUX.1-Kontext-dev (LoRA 방식)
평가 지표 1: CLIP Score, FID
- CLIP Score: Base 모델이 더 높음 → 프롬프트 일치도 우위
- FID Score: LoRA가 낮음 → 실제 이미지 분포에 더 근접
| 지표 | Base 모델 | LoRA 모델 | 우수 모델 |
|---|---|---|---|
| CLIP Score | 24.0207 | 22.0444 | Base |
| FID Score | 66.3546 | 52.4227 | LoRA |
평가 지표 2: GPT 정성 평가 (5점 만점)
| 평가 항목 | Base 평균 | LoRA 평균 | 우수 모델 |
|---|---|---|---|
| 프롬프트 충실도 | 3.28 | 3.82 | LoRA |
| 디자인 품질 | 4.00 | 4.18 | LoRA |
| 브랜드 정체성 | 4.18 | 4.27 | LoRA |
| 이미지 품질 | 4.64 | 4.55 | Base |
[텍스트 모델 학습 결과] kanana-1.5-8b-instruct-2505 파인튜닝 결과
평가지표 1: BERTScore (Precision, Recall, F1)
| 실험 | 학습 조건 | BERTScore-F1 변화 | 분석 |
|---|---|---|---|
| 1차 | 5 epoch, batch size 4, LoRA 적용 | 0.6977 → 0.7058 (+0.0081 ↑) | 응답 품질 소폭 향상, 할루시네이션 및 일관성 발견 |
| 2차 | 3 epoch, batch size 2, LoRA 적용 | 0.7344 → 0.8884 (+0.1540 ↑) | 응답 품질 대폭 향상, 할루시네이션 및 일관성 여전히 발견 |
| 3차 | 5 epoch, batch size 2, LoRA 적용 | 0.8011 → 0.9161 (+0.1150 ↑) | 응답 품질 대폭 향상, 할루시네이션 및 일관성 제거 |
평가지표 2: Cosine Similarity
| 지표 | Base | Finetuned | 변화 |
|---|---|---|---|
| CosineSim | 0.9004 | 0.9526 | +0.0523 |
- 파인튜닝 모델이 문맥 유사도에서 높은 일치도 확보
- 응답 의미 일관성과 정보 정합성 개선
📌 AI 파이프라인 총괄
기본 흐름:
사용자 입력 → Intent 분류
→ (1) 이미지 생성 / (2) 이미지 수정 / (3) RAG / (4) 일반 대화
→ 체크리스트 HITL → 이미지 쿼리 생성 → FLUX 생성
→ 선택(수정/재생성) → 3D 변환 → 4D 변환 → S3 저장
✔ Intent Classifier
🔹 초기 사용자 의도에 따라 파이프라인 분기
🔹 4가지 사용자 시나리오 처리: 체크리스트 기반 이미지 생성 / 직접 이미지 생성 / 이미지 수정 / 일반 지식 질문
🔹 rag / image_generation / image_modification / general_conversation
1. 시나리오를 반영하기 위한 Intent classifier AI 프롬프트
INITIAL_INTENT_CLASSIFICATION_PROMPT = """다음 사용자 질문의 의도를 분류해주세요:
사용자 질문: {user_query}
의도 분류 옵션:
1. rag: 현대자동차나 자동차에 대한 구체적인 지식 질문 (기술, 디자인, 철학, 역사 등)
2. image_generation: 새로운 자동차 이미지 생성 요청 (예: "자동차 이미지 만들어줘", "새로운 디자인 생성해줘", "이미지 생성")
3. image_modification: 이미지 수정 요청 (예: "이미지 수정해줘", "이 차 색깔 바꿔줘", "이미지 업로드해서 수정", "이미지 수정")
4. general_conversation: 일반적인 일상 대화 (인사, 날씨, 개인적인 질문, 자동차와 무관한 일반적인 대화 등)
반드시 다음 중 하나의 키워드만 답변하세요: rag, image_generation, image_modification, general_conversation"""
2. 초기 분류를 위한 노드 함수 정의
def classify_and_apply_intent(state: PipelineState) -> Dict[str, Any]:
print(f"[분기] classify_and_apply_intent 노드 접근")
user_query = state.get("user_query", "")
final_intent = _classifier.classify_initial_intent(user_query)
print(f"[처리] 의도 분류 완료: '{user_query[:30]}...' -> '{final_intent}'")
# image_generation 경로로 갈 때 image_mode에서 interrupt 발생
if final_intent == "image_generation":
state["waiting_node"] = "image_mode"
return {"initial_intent": final_intent}
def route_top(state: PipelineState) -> str:
it = _norm(state.get("initial_intent"))
print(f"[라우팅] route_top - 의도: '{it}'")
if it == "image_generation":
print(f"[라우팅] 이미지 생성 경로로 라우팅")
return "image_generation"
elif it == "image_modification":
print(f"[라우팅] 이미지 수정 경로로 라우팅")
return "image_modification"
elif it == "rag":
print(f"[라우팅] RAG 질문 경로로 라우팅")
return "rag"
else:
# Interrupt 걸리기 전, 첫 방문 시
if state["waiting_node"] != "route_top":
interrupt({"is_loading": True, "generation_type": "text"})
else:
print(f"[라우팅] 일반 대화 경로로 라우팅")
return "general_conversation"
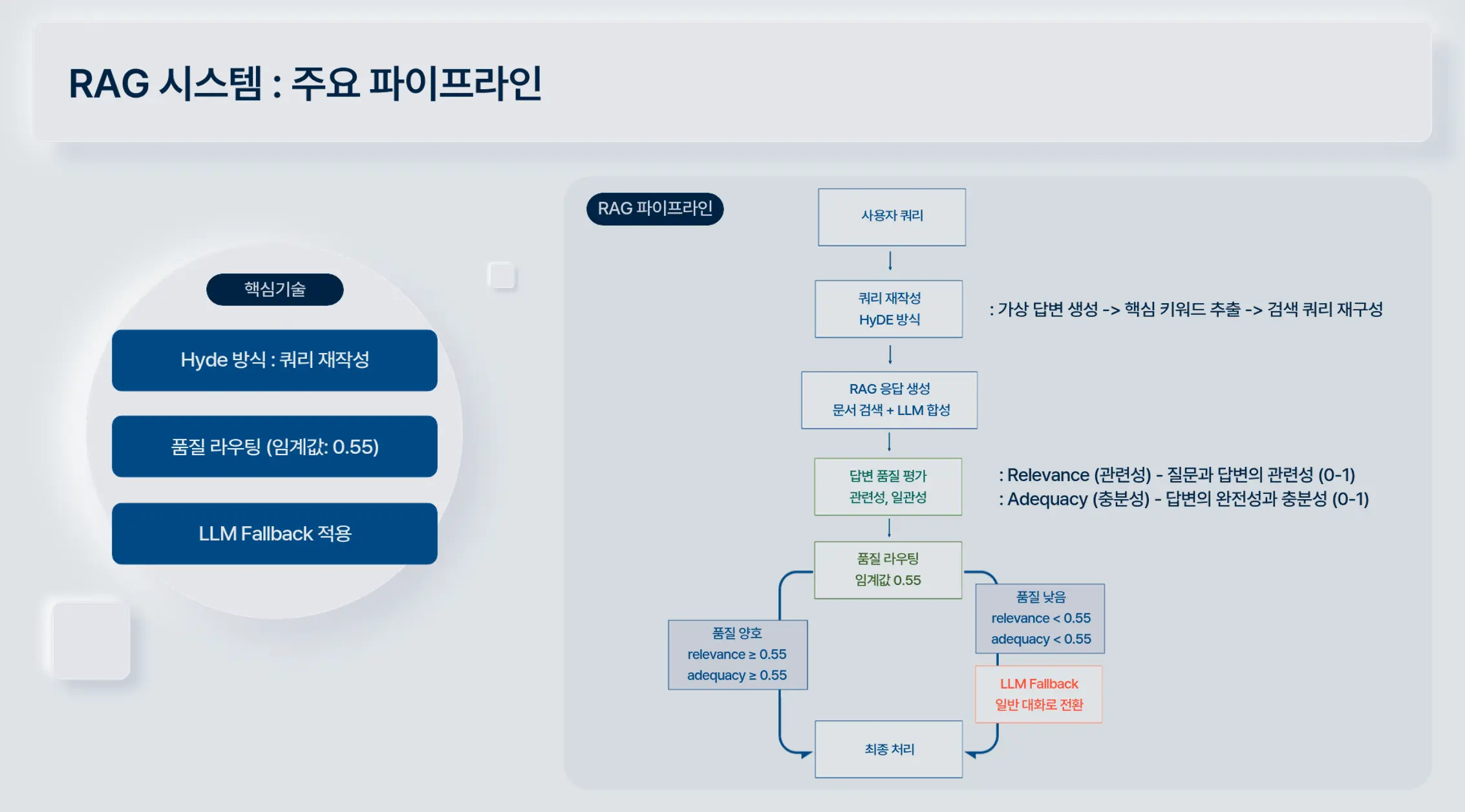
✔ RAG 흐름
🔹 Query Rewrite (HyDE)
🔹 Qdrant Vector 검색
🔹 Reranker
🔹 답변 품질 평가
🔹 LLM fallback
✔ 이미지 생성 파이프라인
🔹 체크리스트 기반 HITL
🔹 Direct Prompt 생성
🔹 FLUX → 수정 → 3D/4D
1. 이미지 쿼리 생성을 위한 체크리스트 텍스트 파이프라인
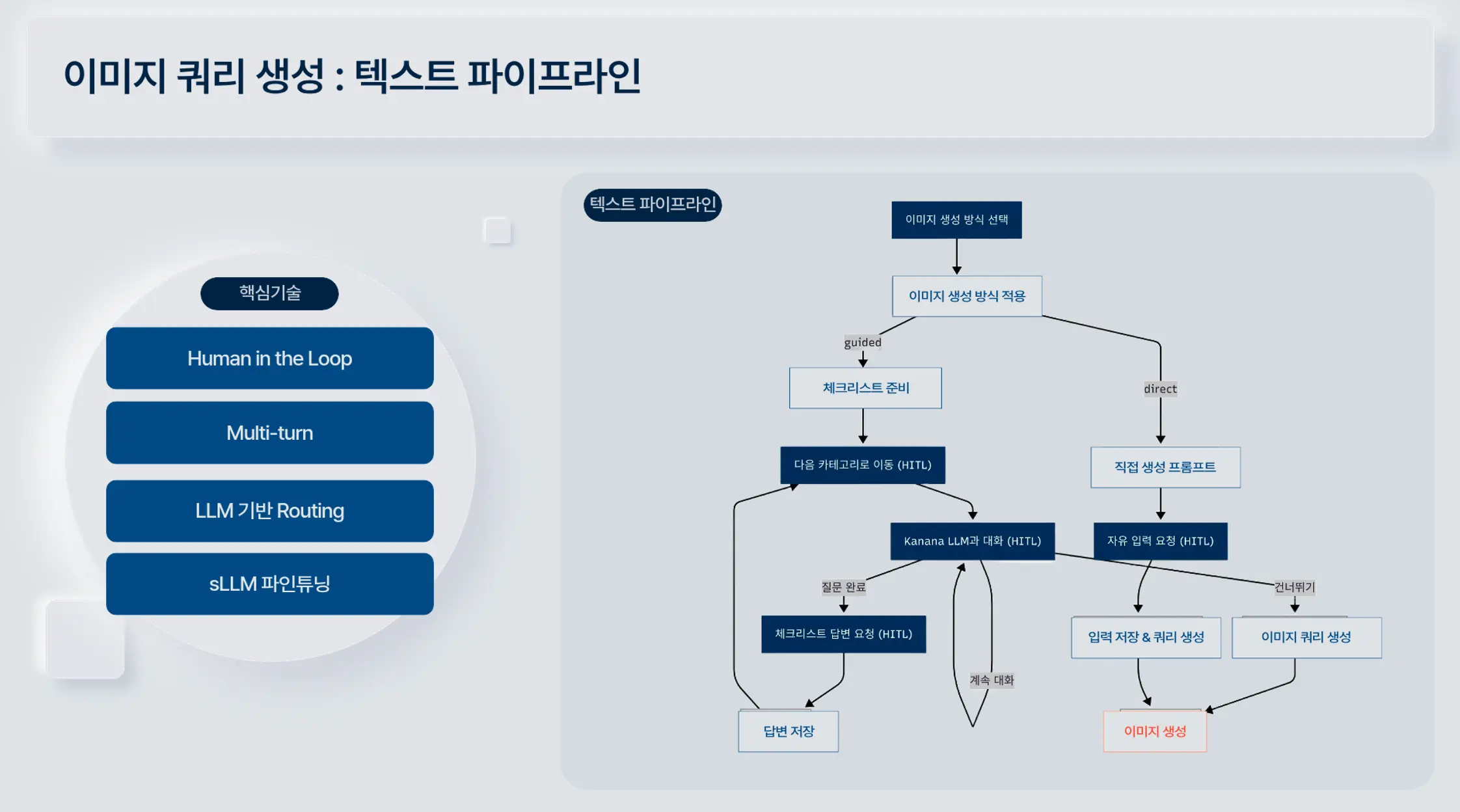
2. 이미지 생성 및 3D/4D 변환 파이프라인
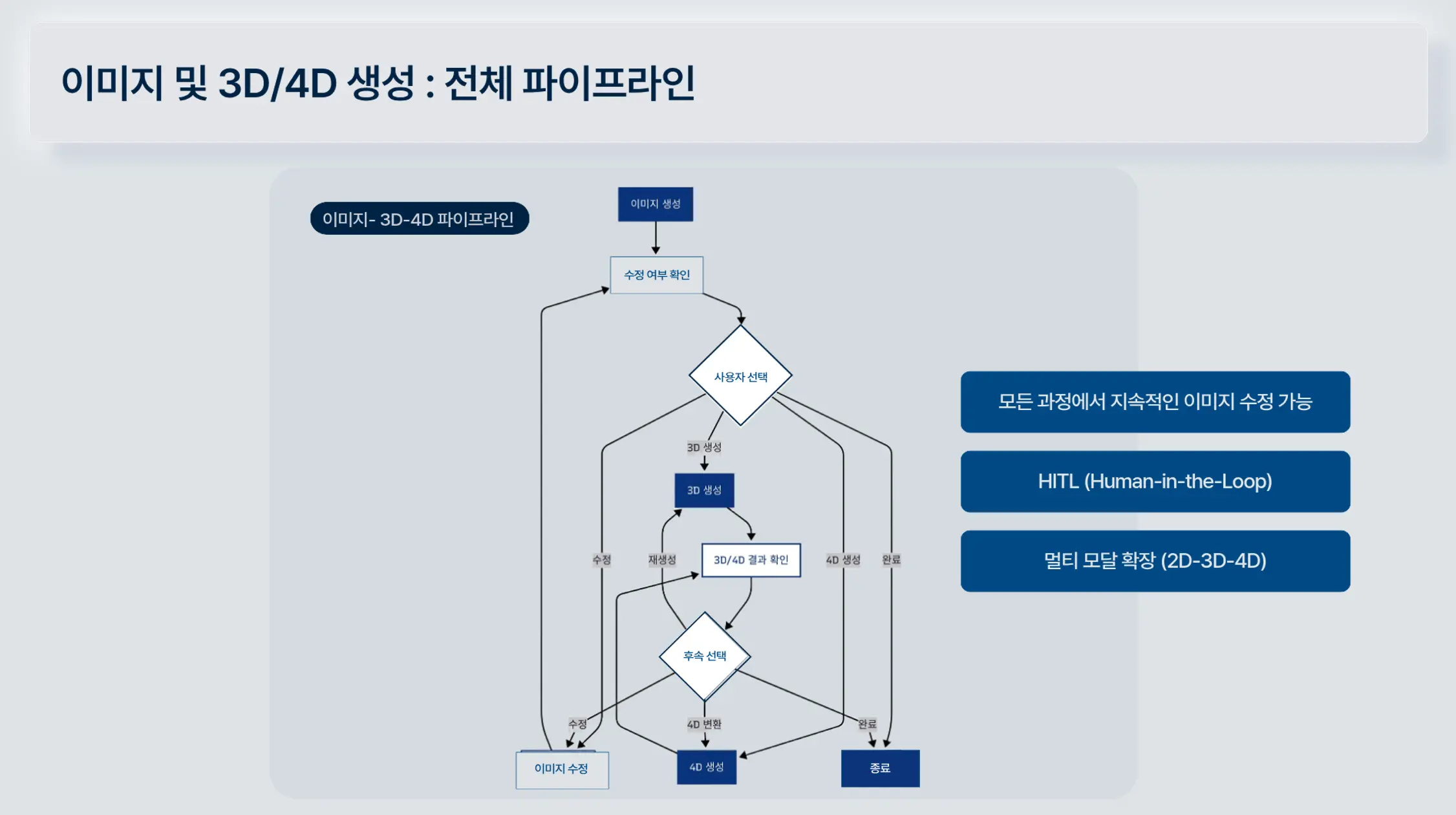
✔ Human-in-the-Loop
🔹 LangGraph interrupt + MemorySaver
🔹 사용자 개입 기반 상태 저장/복원
📌 ERD 설계